
以下各题都是从网上获取,答案为个人理解及资料查询,以便自己查漏补缺
以下题目获取于博客
基础常见
-
列举出5个常用Python标准库
os:提供与系统相关操作的函数sys:通常用于命令行参数re:正则匹配math:数学运算datetime:日期处理函数logging:日志处理函数
-
Python 内建数据类型有哪些?
- 整形(int)、浮点型(float)、布尔型(False/True)、字符串(str)、列表(list)、元组(tuple)、字典(dict)、集合(set)等
-
简述 with 方法打开处理文件帮我我们做了什么?
- 首先相当于用open函数打开文件,然后进行文件操作,等操作完成时,它会帮我们自动调用close函数关闭文件
try: f = open('./test.txt','wb') f.write('hello python') except: print('open error') finally: f.close() -
列出 Python 中可变数据类型和不可变数据类型,为什么?
- 可变数据类型:列表、字典、集合
- 不可变数据类型:整形、浮点型、字符串型、元组
- 在Python中,可以说万物皆对象,比如说把
a = 1和b = 1,这时其实 a 和 b 都指向的是 1 这个对象,当这时 a 和 b 的值变了,a和b的指向也就变了,可以 id() 观察,所以在可以大概根据数据是否可变来判断是否可变数据类型,像字典、列表这种数据类型,其中的数据发生改变,这块数据的id是不会发生改变的,所以它们是可变数据类型
-
Python 获取当前日期
- 可以用datetime模块,然后也可加上strftime模块对时间模块进行格式化
import datetime today = date.date.today() today_1 = today.strftime('%y-%m-%d') -
统计字符串每个单词出现的次数
def count_each_char_1(string): res = {} for i in string: if i not in res: res[i] = 1 else: res[i] += 1 return res def count_each_char_2(string): res = {} for i in string: res[i] = res.get(i,0)+1 return res -
用 python 删除文件和用 linux 命令删除文件方法
- python:
os.remove(filename) - linux:
rm filename
- python:
-
写一段自定义异常代码
- 可以自定义异常类,然后继承于Exception
class MyException(Exception): def __init__(self,err='我定义的异常'): Exception.__init__(self,err) -
举例说明异常模块中 try except else finally 的相关意义
- try下的是可能出现异常的代码,except是代码异常后需要执行的代码,else是没有出现异常要执行的代码,finally是不管是否出现异常都需要执行的代码
-
遇到 bug 如何处理
- 一般通过调试定位Bug位置
语言特性
- 谈谈对 Python 和其他语言的区别
- 优点:代码简洁、优雅,但对代码格式要求严格,是一门解释型语言,边编译边执行,所以调试的时候比较方便,但因此执行速度相对其他编译型语言执行速度会慢一点
- 缺点:上面有提到的执行速度会较慢,还有就是对于CPython解释器会有GIL(全局解释器锁)
- 简述解释型和编译型编程语言
- 解释型语言:不需要预先编译,是边编译边执行的
- 编译型语言:首先把源代码编译成机器语言,之后就直接执行编译后的结果
- Python 的解释器种类以及相关特点?
- CPython:用C语言开发的,只是使用最广的解释器,会有GIL
- IPython:这是一款交互式的解释器
- JPython:它会把代码运行在Java的解释器上,把代码编译成Java字节码执行
- PyPy:采用JIT技术,对代码进行动态编译,提高了执行效率
- IronPython:运行在.NET平台上,把Python编译成.NET字节码
- 说说你知道的Python3 和 Python2 之间的区别?
print:py2是print语句,后面直接跟需要打印的东西即可;py3是print函数,意味着需要加括号调用函数- 编码:py2默认的编码是ascli,所以有中文时一般编写代码时会在最开头用coding声明下utf-8格式;而py3默认的编码是utf-8
range:在py2中它返回的是一个列表,而在py3中它返回的是一个生成器input:py2中input得到是int类型,用raw_input得到的才是str类型;py3中input得到的是str类型
- Python3 和 Python2 中 int 和 long 区别?
- py2中有long类型;py3中把long类型和int类型结合了,没有long类型
xrange和range的区别- 在py2中range生成返回的是一个列表,用xrange则返回的是一个生成器;但在py3中,并没有xrange,range直接返回的就是一个生成器
编码规范
-
什么是 PEP8?
- 它是python编码的规范,如缩进建议使用4个空格,每行最大长度为79,模块的导入顺序等等
-
了解 Python 之禅么?
- 输入
import this,就会出现经典的python之禅 - 总结一句话就是:保持简洁,追求优雅,用最简单的代码完成最复杂的功能(额。。大概就是这意思吧)
- 输入
-
了解
docstring么?- 它在python中的作用是为函数、模块和类注释生成文档
-
了解类型注解么?
-
在传入参数时指定参数的类型,仅仅是为了对阅读者的方便,在程序执行中并没有作用
def demo(x: int, y: int) -> int: return x + y
-
-
例举你知道 Python 对象的命名规范,例如方法或者类等
- 方法一般用小写加下划线,然后类一般用驼峰法等
-
Python 中的注释有几种?
- 有块注释和行注释
-
如何优雅的给一个函数加注释?
- 函数下用三引号对函数功能的描述,参数要求及返回值进行注释
-
如何给变量加注释?
- 一般变量名应该与变量的作用相关,如需要加注释在变量名上#号跟注释就好
-
Python 代码缩进中是否支持 Tab 键和空格混用
- 不支持,根据PEP8规范建议使用4个空格
-
是否可以在一句 import 中导入多个库?
- 可以是可以,用逗号隔开,但可读性不好,根据PEP8规范建议一行一个import导入一个库
-
在给 Py 文件命名的时候需要注意什么?
- 最好用小写字母加下划线,避免与内置函数重名,不要使用数字开头
-
例举几个规范 Python 代码风格的工具
- 自动检测工具Pylint、自动优化工具black、Autopep8
数据类型
字符串
-
列举 Python 中的基本数据类型?
- int、float、str、list、dict、tuple
-
如何区别可变数据类型和不可变数据类型
- 看更改数据值后,索引的指向会不会改变;int、float、tuple为不可变数据类型;list、dict为可变数据类型
-
将
"hello world"转换为首字母大写"Hello World"- 使用capitalize方法即可
-
如何检测字符串中只含有数字?
- 使用isdigit方法
-
将字符串
"ilovechina"进行反转- reverse方法(适用于列表),可以用
''.join(reversed('ilovechina')) 'ilovechina'[::-1]
- reverse方法(适用于列表),可以用
-
Python 中的字符串格式化方式你知道哪些?
'{}'.format()、'%s' % xxx
-
有一个字符串开头和末尾都有空格,比如“ adabdw ”,要求写一个函数把这个字符串的前后空格都去掉
rstrip():末尾的空白、lstrip():开头空白、strip():两端的空白- 但得注意的是这种删除只是暂时的,要想永久删除,只需把原先的索引指向删除后的值即可
-
获取字符串
''123456''最后的两个字符[-2:]
-
一个编码为 GBK 的字符串 S,要将其转成 UTF-8 编码的字符串,应如何操作?
S.encode().decode("utf-8")
-
(1)
s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong'](2)a = “你好 中国 “,去除多余空格只留一个空格
re.split(" |\:", s)replace()方法
-
(1)怎样将字符串转换为小写
(2)单引号、双引号、三引号的区别?
lower()方法- 单引号和双引号代表字符串,三引号表示块
列表
- 已知
AList = [1,2,3,1,2],对 AList 列表元素去重,写出具体过程- 可以利用set集合的特性进行去重,先把列表转换成set集合,在转回list
list(set(AList))
- 如何实现 “1,2,3” 变成 [“1”,”2”,”3”]
split(',')
- 给定两个 list,A 和 B,找出相同元素和不同元素
- 同样可以利用set的特性,先转成set类型,然后两列表交集就是相同部分,两列表并集减去交集就是不同部分
(set(A)&set(B))、(set(A)|set(B))-(set(A)&set(B))
[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]- 列表推导式:
x = [j for i in l for j in i]
- 列表推导式:
- 合并列表
[1,5,7,9]和[2,2,6,8]- +就好了,也可以用
extend()方法
- +就好了,也可以用
- 如何打乱一个列表的元素?
- 用random模块中的shuffle()方法
字典
-
字典操作中 del 和 pop 有什么区别
- del可以删除指定元素;pop可以删除最后一个元素,并把该元素返回
-
按照字典内的年龄排序
sorted(dict, key=lambda x:x["age"])dict.sort(key=lambda x:x["age"])
-
请合并下面两个字典
a = {"A":1,"B":2},b = {"C":3,"D":4}- 可以使用upadte()方法,
a.update(b) - 也可以用解包方式,
{**a, **b}
- 可以使用upadte()方法,
-
如何使用生成器的方式生成一个字典,写一段功能代码
# 把字典的 key 和 value 值调换 d = {'a':'1', 'b':'2'} print({v:k for k,v in d.items()}) -
如何把元组
("a","b")和元组(1,2),变为字典{"a":1,"b":2}- 使用zip方法,
dict(zip(a, b))
- 使用zip方法,
综合
-
下列字典对象键类型不正确的是?
A:{1:0,2:0,3:0} B:{“a”:0, “b”:0, “c”:0} C: {(1,2):0, (2,3):0} D: {[1,2]:0, [2,3]:0}
- D,因为只有可以可以hash的对象才可以做字典的键,列表是不可hash对象
-
如何交换字典
{"A":1,"B":2}的键和值?- 如上
dict(zip(s.values(),s.keys()))
-
Python 里面如何实现 tuple 和 list 的转换?
- 直接使用
list()或tuple()函数即可
- 直接使用
-
我们知道对于列表可以使用切片操作进行部分元素的选择,那么如何对生成器类型的对象实现相同的功能呢?
-
这个题目考察了 Python 标准库的 itertools 模快的掌握情况,该模块提供了操作生成器的一些方法。 对于生成器类型我们使用 islice 方法来实现切片的功能
from itertools import islice gen = iter(range(10)) #iter()函数用来生成迭代器 #第一个参数是迭代器,第二个参数起始索引,第三个参数结束索引,不支持负数索引 for i in islice(gen,0,4): print(i)
-
-
请将
[i for i in range(3)]改成生成器(i for i in range(3))iter(range())
-
a="hello"和b="你好"编码成 bytes 类型- 法1:在前面加个b ===>
a = b'hello' - 法2:bytes方法 ===>
b = bytes("你好", "utf-8") - 法3:encode方法 ===>
b = "你好".encode("utf-8")
- 法1:在前面加个b ===>
-
下面的代码输出结果是什么?
a = (1,2,3,[4,5,6,7],8) a[2] = 2- 首先得知道元组是不可以变数据类型,所以改变元组里面的值,它会直接报错
-
下面的代码输出的结果是什么?
a = (1,2,3,[4,5,6,7],8) a[3][0] = 2- 虽然说元组是不可变数据类型,但如果元组里面的元素是可变类型的,然后又是在操作该元素,其元组的内存地址是不会变的,所以该操作会把元组里面列表的第一个元素改成4
操作类题目
-
Python 交换两个变量的值
- 可以采用语法糖:
a, b = b, a
- 可以采用语法糖:
-
在读文件操作的时候会使用 read、readline 或者 readlines,简述它们各自的作用
read:读取整个文件readline:读取下一行,for循环中经常用readlines读取整个文件到一个迭代器,for中也可以
-
json 序列化时,可以处理的数据类型有哪些?如何定制支持 datetime 类型?
-
可以处理的数据类型是 string、int、list、tuple、dict、bool、null
-
json.dumps()===> 将Python中的对象转换为JSON中的字符串对象 -
json.loads()===> 将JSON中的字符串对象转换为Python中的对象# 自定义时间序列化 import json from json import JSONEncoder from datetime import datetime class ComplexEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, datetime): return obj.strftime('%Y-%m-%d %H:%M:%S') else: return super(ComplexEncoder,self).default(obj) d = { 'name':'alex','data':datetime.now()} print(json.dumps(d,cls=ComplexEncoder)) # {"name": "alex", "data": "2018-05-18 19:52:05"}
-
-
json 序列化时,默认遇到中文会转换成 unicode,如果想要保留中文怎么办?
import json a=json.dumps({"ddf":"你好"},ensure_ascii=False) print(a) #{"ddf": "你好"} -
有两个磁盘文件 A 和 B,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列),输出到一个新文件 C 中
with open("a.txt") as A: content_a = A.readline() with open("b.txt") as B: content_b = B.readline() with open("c.txt","w+") as C: content_c = ''.join(sorted(content_a+content_b)) C.write(content_c) -
如果当前的日期为 20190530,要求写一个函数输出 N 天后的日期,(比如 N 为 2,则输出 20190601)
import datetime def getday(n): #datetime.datetime指定日期 the_date = datetime.datetime(2019,5,30) #datetime.timedelta,时间差 result_date = the_date + datetime.timedelta(days = n) target_date = result_date.strftime('%Y%m%d') return target_date print(getday(2)) -
写一个函数,接收整数参数 n,返回一个函数,函数的功能是把函数的参数和 n 相乘并把结果返回
def func1(n) def func2(m) return n*m return func2 -
下面代码会存在什么问题,如何改进?
def strappend(num): str = 'first' for i in range(num): str += str(i) return str- 首先编译会报错,
str()是python的一个内置函数,最好把变量名换一换,按其意思是()应改成[],还有num应该是一个整数,可以加个传参时对其进行一下校验
- 首先编译会报错,
-
一行代码输出 1-100 之间的所有偶数
list(range(2,100,2))
-
with 语句的作用,写一段代码?
-
常用于文本操作,打开文本后自动关闭
with open(r'test.txt', 'r') as f: data = f.read()
-
-
python 字典和 json 字符串相互转化方法
json.loads()===> 将JSON中的字符串对象转换成DICTjson.dumps()===> 将DICT数据JSON中的字符串
-
请写一个 Python 逻辑,计算一个文件中的大写字母数量
with open(file_name, 'r') as f: count = 0 for i in f.read(): if i.isupper(): count += 1 print("大写字母数量为%d" % count) -
请写一段 Python连接 Mongo 数据库,然后的查询代码
import pymongo db_configs = { 'type': 'mongo', 'host': '地址', 'port': '端口', 'user': 'spider_data', 'passwd': '密码', 'db_name': 'spider_data' } class Mongo(): def __init__(self, db=db_configs["db_name"], username=db_configs["user"], password=db_configs["passwd"]): self.client = pymongo.MongoClient(f'mongodb://{db_configs["host"]}:db_configs["port"]') self.username = username self.password = password if self.username and self.password: self.db1 = self.client[db].authenticate(self.username, self.password) self.db1 = self.client[db] def find_data(self): # 获取状态为0的数据 data = self.db1.test.find({"status": 0}) gen = (item for item in data) return gen if __name__ == '__main__': m = Mongo() print(m.find_data()) -
说一说 Redis 的基本类型
- redis一共分为五种基本类型
- string类型:它在Redis 中是以二进制存储的,所以该类型可以接受任何格式的数据
- hash类型:Hash类型是String类型的filed和value的映射表,或者说是一个String的结合,他特别适合存储对象
- list类型:List类型是一个链表结构的集合,其主要功能有push,pop获取元素等等
- set类型:set集合是String类型的无序集合,set是通过hashtable实现的,对集合我们可以取交集,并集,差集
- zset类型:Zset是在set的基础上做了一个有序的调整
- redis一共分为五种基本类型
-
请写一段 Python连接 Redis 数据库的代码
import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 r = redis.Redis(host='localhost', port=6379, decode_responses=True) # host是redis主机,需要redis服务端和客户端都启动 redis默认端口是6379 r.set('name', 'junxi') # key是"foo" value是"bar" 将键值对存入redis缓存 print(r['name']) print(r.get('name')) # 取出键name对应的值 print(type(r.get('name'))) -
请写一段 Python 连接 MySQL 数据库的代码
#导入pymysql的包 import pymysql #获取一个数据库连接,注意如果是UTF-8类型的,需要制定数据库 conn=pymysql.connect(host='localhost',user='pythontab',passwd='pythontab',db='pythontab',port=3306,charset='utf8') cur=conn.cursor()#获取一个游标 cur.execute('select * from user') data=cur.fetchall() for d in data : #注意int类型需要使用str函数转义 print("ID: "+str(d[0])+' 用户名: '+d[1]+" 注册时间: "+d[2]) cur.close()#关闭游标 conn.close()#释放数据库资源 -
了解 Redis 的事务么?
- Redis事务可以一次执行多个命令,要么都执行成功,要么都执行不成功,但Redis的事务与MySQL中的事务有所不同,Redis中事务没有回滚
- 一个事务从开始到执行会经历三个阶段:开始事务、命令入列、执行事务
-
了解数据库的三范式么?
- 第一范式(确保每列保持原子性):第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表
- 第二范式(确保表中的每列都和主键相关):第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中
- 第三范式(确保每列都和主键列直接相关,而不是间接相关):第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关
-
了解分布式锁么?
-
需具备的条件
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行; 2、高可用的获取锁与释放锁; 3、高性能的获取锁与释放锁; 4、具备可重入特性; 5、具备锁失效机制,防止死锁; 6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
-
用 Python 实现一个 Reids 的分布式锁的功能
-
写一段 Python 使用 Mongo 数据库创建索引的代码
高级特性
-
函数装饰器有什么作用?请列举说明?
- 其本质上就是一个函数,它可以让其它函数不做任何代码修改的前提下增加额外的功能,装饰器的返回值也是一个函数
- 它可以实现很多功能,如:插入日志、性能测试、事务处理、权限校验等;也可以把一些多处需要用到相同的代码封装到一个装饰器里面,如登录校验的装饰器
-
Python 垃圾回收机制?
- python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
- 引用计数优点:简单;实时性,一旦没有引用,内存就直接释放了
- 缺点:维护引用计数消耗资源;循环引用,这是最致命的,所占用的内存永远无法回收
-
魔法函数
__call__怎么使用?-
Python中,只要在创建类型的时候定义了
__call__()方法,这个类型就是可调用的。
__doc__ 类(实例).__doc__ 类的描述信息 '''class des''' __module__ 类(实例).__module__ 表示当前操作的对象在那个模块 __class__ 表示当前操作的对象的类是什么 __call__ 类(实例)调用时(加括号)执行 __dict__查看类或实例的所有属性结果 为字典 __str__打印对象时执行 _call__ 在Python中,函数其实是一个对象: >>> f = abs >>> f.__name__ 'abs' >>> f(-123) 123 由于 f 可以被调用,所以,f 被称为可调用对象。 所有的函数都是可调用对象。 一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__() -
如何判断一个对象是函数还是方法?
- 用内置的
isinstance()来判断
- 用内置的
-
@classmethod 和@staticmethod 用法和区别
- @staticmethod:静态方法,类似于全局函数,不需要实例化也能调用
- @classmethod:类方法,必须实例化类以后才能使用,同时第一个参数由self变化为cls
-
Python 中的接口如何实现?
-
Python 中的反射了解么?
-
metaclass(元类) 作用?以及应用场景?
-
hasattr() getattr() setattr()的用法- 看第7题
-
请列举你知道的 Python 的魔法方法及用途
- 看第三题
- 这里也可参考了解
-
如何知道一个 Python 对象的类型?
type()
-
Python 的传参是传值还是传址?
- 在python中,可以说是万物皆对象,它传递参数时,实际是传递的对象的引用,也相当于是传值和传址的一种结合
-
Python 中的元类(metaclass)使用举例
- 猴子补丁,可看第8题里的链接
-
简述 any()和 all()方法
any()===> 主要用来判断对象中的是否全为空值,若是返回False,否则Trueall()===> 主要用来判断对象中的值是否存在空值,只要存在一个空值,就返回False,否则True
-
filter 方法求出列表所有奇数并构造新列表,
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]-
filter(过滤函数, 可迭代对象)函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表a = [1,2,3,4,5,6,7,8,9,10] def func(n): return n % 2 == 0 res = list(filter(func, a)) print(res)
-
-
什么是猴子补丁?
- 在运行代码的过程中,对某个方法或者属性进行替换的行为称为猴子补丁,就比如说在协程gevent中,一般都会在开头加一句
monkey.patch_all(),它会把下面的延时操作都变成gevent.sleep() - 详细解析进点这
- 在运行代码的过程中,对某个方法或者属性进行替换的行为称为猴子补丁,就比如说在协程gevent中,一般都会在开头加一句
-
在 Python 中是如何管理内存的?
- python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅来管理内存
- 详细可看上面第2题
- 内存的分配有四种方式
- 从静态存储区域分配:存在程序编译的时候就已经分配好,存放全局变量和静态变量,这些内存在程序运行期间都存在
- 在栈上创建:由编译器自动分配自动释放,用于存放局部变量和参数,栈内的对象先进后出,所以先创建的对象会后析构。栈由于是编译器自动管理的,所以栈内的对象不会存在内存泄露问题,并且效率很高,但是分配的内存容量有限。
- 从堆上分配,亦称动态内存分配:程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
- 常量区:存放常量字符串,程序结束后由系统释放
-
当退出 Python 时是否释放所有内存分配?
- 具有对象循环引用或者全局命名空间引用的变量退出时会被释放
- 不会释放c库保留的内存部分
正则表达式
-
使用正则表达式匹配出
<html><h1>www.baidu.com</html>中的地址import re res = re.findall(r'<html><h1>(.*?)</html>','<html><h1>www.baidu.com</html>') print(res) -
a=”张明 98 分”,用
re.sub,将 98 替换为 100import re a = "张明98分" res = re.sub('98', '100', a) print(res) -
正则表达式匹配中
(.*)和(.*?)匹配区别?- 无问号默认为贪婪模式,即尽可能的多匹配字符,例如ab匹配abbb结果为abbb,若加上问号ab?则变为非贪婪模式,尽可能匹配更少的字符,匹配结果为a
- 还有如果没有括号的话,?表示前一字符出现0或1次
-
写一段匹配邮箱的正则表达式
[0-9a-zA-Z]+@[0-9a-zA-Z]+\.(?:com|cn|net)
其它内容
-
解释一下 python 中 pass 语句的作用?
- 通常作为一个占位符来使用,当程序执行到它时,会直接跳过
-
简述你对 input()函数的理解?
- 它为一个输入函数,接受用户输入的值,在py2中默认是int类型,在py3中默认是str类型
-
python 中的 is 和==
- is是检查对应的内存地址是否相同,==只是检查值是否相同
-
Python 中的作用域
- 作用域指的是函数名或者变量名的寻找顺序,优先级从高到低分别为:局部作用域(子函数)、闭包函数外的函数中(父函数)、全局作用域(当前python模块)、内建作用域(python标准库)
-
三元运算写法和应用场景?
a = 'a' if b>1 else 'b'- 个人感觉没有什么特殊的应用场景,只是if语句的简写而已
-
了解 enumerate 么?
-
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 -
enumerate(sequence, [start=0]):sequence – 一个序列、迭代器或其他支持迭代对象;start – 下标起始位置。a = [1,2,3] for i,x in enumerate(a,1): i为索引值,x为a列表中的元素 print(i,x) ================ 1 1 2 2 3 3
-
-
列举 5 个 Python 中的标准模块
- time(延时、日期)、re(正则)、random(随机)、urllib(网络请求)、os(系统)、csv(csv文件读写)、hashlib(哈希处理)、logging(日志)
-
如何在函数中设置一个全局变量
- 使用global关键字,若想改变全局变量a的值,需
global a,然后在修改
- 使用global关键字,若想改变全局变量a的值,需
-
pathlib 的用法举例
- 常用操作可以看一下这里
-
Python 中的异常处理,写一个简单的应用场景
try: f = open('filename', 'r') f.readlines() except: print('open error') finally: f.close() -
Python 中递归的最大次数,那如何突破呢?
-
默认递归最大次数为1000,可以通过以下代码修改
import sys sys.setrecursionlimit(10000) -
不同的系统还存在解释器的上限,Windows约为4400次,Linux约为24900次
-
-
什么是面向对象的 mro
- MRO(Method Resolution Order):基类解析顺序。指对象在继承或多次继承后,方法的解析顺序。
- 看这里
-
isinstance 作用以及应用场景?
-
isinstance(object, classinfo)classinfo – 可以是直接或间接类名、基本类型或者由它们组成的元组。 isinstance()函数来判断一个对象是否是一个已知的类型,类似type()type()不会认为子类是一种父类类型,不考虑继承关系isinstance()会认为子类是一种父类类型,考虑继承关系
-
-
什么是断言?应用场景?
- 断言也是一种异常处理的方式,可以判断关键字后方的表达式是否为真,若为真则继续执行,若为假则抛出异常。常用于测试
-
lambda 表达式格式以及应用场景?
- 它可以创建匿名函数,用于一些简单的函数处理,如:
res = lambda x,y: x + y,这里传入xy的值,返回xy的和,常与循环结合使用
- 它可以创建匿名函数,用于一些简单的函数处理,如:
-
新式类和旧式类的区别
- 新式类都是继承于object,而旧式类就不需要
- 新式类的MRO算法采用C3算法广度优先搜索,而旧式类MRO算法为深度优先搜索
- 形式类相同父类只执行一次,而经典类重复执行多次
-
dir()是干什么用的?- 显示对象的属性和方法
-
一个包里有三个模块,demo1.py, demo2.py, demo3.py,但使用 from tools import *导入模块时,如何保证只有 demo1、demo3 被导入了
from tools import demo1, demo3 -
列举 5 个 Python 中的异常类型以及其含义
- ImportError:导入模块失败;NameError:未声明对象;TabError:Tab和空格混用;GeneratorExit:生成器发生异常来通知退出;AssertionError:断言失败
- 更多
-
copy 和 deepcopy 的区别是什么?
copy.copy()是浅拷贝,拷贝时只是拷贝索引指向,里面的数据不会拷贝,而且无法拷贝元组copy.deepcopy()是深拷贝,它会把里面的索引指向的数据也拷贝,重新建一个新的空间- 感觉我的解释不够全面,可以看下这里
-
代码中经常遇到的*args, **kwargs 含义及用法
- 用于函数的定义,有时预先会不确定传递多少个参数,这时就可使用它们,这样有助于函数的功能的扩展;
*arg会把多出来的位置参数转化为tuple,**kwarg会把关键字参数转化为dict - 详细用法
- 用于函数的定义,有时预先会不确定传递多少个参数,这时就可使用它们,这样有助于函数的功能的扩展;
-
Python 中会有函数或成员变量包含单下划线前缀和结尾,和双下划线前缀结尾,区别是什么?
- 单下划线前缀表示私有变量或函数,不能直接调用;双下划线前缀代表类的私有方法,只有本身可以访问;双下划线前缀结尾代表特殊方法
-
w、a+、wb 文件写入模式的区别
- w 为写模式,会覆盖旧的内容,写入形式为字符串
- a+ 为追加模式,会在原有的内容后面写入,写入形式为字符串
- wb 写模式,会覆盖,写入形式为二进制
-
举例 sort 和 sorted 的区别
- 使用方法上:
list.sort()、sorted(list) - 结果上:sort()会改变原有对象的排列顺序,而sorted()只是返回排列后的值,并不影响原有对象
- 使用方法上:
-
什么是负索引?
- 从尾开始数,-1为最后一个
-
pprint 模块是干什么的?
- 与print的功能类似,也是用于输出,只是输出更美化好看
-
解释一下 Python 中的赋值运算符
- 这个感觉没啥好说的,可以看一下这里
-
解释一下 Python 中的逻辑运算符
- 也可以看上一题
-
讲讲 Python 中的位运算符
- 就是把数字当成二进制来计算,可以看27题链接
-
在 Python 中如何使用多进制数字?
- 在数字前加前缀,0b/0B表示二进制数,0o/0O表示8进制数,0x/0X表示16进制
-
怎样声明多个变量并赋值?
a, b = 1, 2
数据结构和算法
-
已知:AList = [1,2,3],BSet = {1,2,3}
(1) 从 AList 和 BSet 中 查找 4,最坏时间复杂度哪个大?
(2) 从 AList 和 BSet 中 插入 4,最坏时间复杂度哪个大?
-
用 Python 实现一个二分查找的函数
def binar_search(alist, item): '''二分查找,递归版''' n = len(alist) if n > 0: mid = n // 2 if alist[mid] == item: return True elif item < alist[mid]: return binar_search(alist[:mid], item) else: return binar_search(alist[mid+1:],item) return False def binar_search_1(alist, item): '''二分查找,非递归版本''' n = len(alist) first = 0 last = n-1 while first <= last: mid = (first + last) // 2 if alist[mid] == item: return True elif item < alist[mid]: last = mid - 1 else: first = mid + 1 return False -
python 单例模式的实现方法
- 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
- 可以使用模块、
__new__、装饰器(decorator)、元类(metaclass)来实现 - 可以参考这里
-
使用 Python 实现一个斐波那契数列
-
数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …
nums = list() a, b, i = 0, 1, 0 while i < 10: nums.append(a) a, b = b, a + b i += 1 for num in nums: print(num) -
多种解法可以点这里
-
-
找出列表中的重复数字
-
找出列表中的单个数字
-
写一个冒泡排序
def fun(list): for i in range(0, len(list) - 1):#外层循环,每个元素都参与一次比较 for j in range(0, len(list) - 1 - i):#内部循环,每个元素只与自己后面的元素做比较 if x[j] < x[j+1]: x[j], x[j+1] =x[j+1], x[j] #互换元素位置 return list #返回排序好的列表 -
写一个快速排序
其它
-
TCP/UDP/HTTP协议的区别
- TCP/IP是个协议组,分为网络层、传输层和应用层;TCP/UDP在传输层,HTTP在应用层,因此,HTTP协议是从web服务器传输超文本到本地浏览器的传送协议(超文本传输协议);HTPP协议是建立在请求/响应的的模型上,所以虽然HTTP本身是一个协议,但其最终还是基于TCP的,不过也有人正在研究TCP+UDP混合的HTTP协议。
- TCP(传输控制协议),它是传输层协议,数据包在传输过程中,HTTP是被封装在TCP包内的,面向连接(即传输时需要先建立连接),数据传输可靠,但是传输数据较慢
- UDP(用户数据报协议),它是与TCP相对应的协议,面向非连接,发送数据时不与对方建立连接,直接把数据包发过去,因此,它的不可靠不如TCP协议,但传输速度较快
-
简述一个前端请求的处理流程,在uwsgi/nginx/django之间处理流程
- 首先确定几个概念:
wsgi:一种实现python解析的通用接口标准/协议,是一种通用的接口标准或者接口协议,实现了python web程序与服务器之间交互的通用性uwsgi:一种通信协议,是uWSGI服务器自有的协议,它用于定义传输信息的类型uWSGI:一种python web server或称为Server/Gateway,实现了uwsgi和WSGI两种协议的web服务器,负责响应python的web、请求Nginx:是一个高性能的HTTP和反向代理服务器
- 流程:
- 首先客户端先请求服务资源
- Nginx监听服务器的端口,接收到客户端发送来的请求,解包、分析
- 如果是静态文件请求,会根据Nginx配置的静态文件目录,返回请求资源
- 如果是动态的请求,Nginx就通过配置文件,将请求转交给uWSGI服务器,uWSGI将请求包进行处理然后传给uwsgi
- uwsgi在根据请求调用调用Django程序,处理完成后Django返回给uwsgi
- uwsgi在将返回的数据打包,发送给uWSGI服务器
- uWSGI接收后转发给Nginx,Nginx最终将客户端请求的资源发给客户端
- 首先确定几个概念:
-
redis用过哪些数据结构?怎么保存的
- Redis的数据结构有
list、string、hash、set、zset - Redis是吧数据储存到内存中,但它也会定期把数据写到硬盘中
- 有两种方式保存数据:
- 快照模式(Snapshot):分定时快照和定量快照,即按一定时间或变化一定次数后将数据保存到磁盘中
- 写模式(Append Only File):这种模式下,Redis会把所有修改的命令(如update、set)等保存到一个只能追加的ASAP文件中,当Redis重启时,它会把这个文件里的命令重新执行一遍
- Redis的数据结构有
-
celery队列
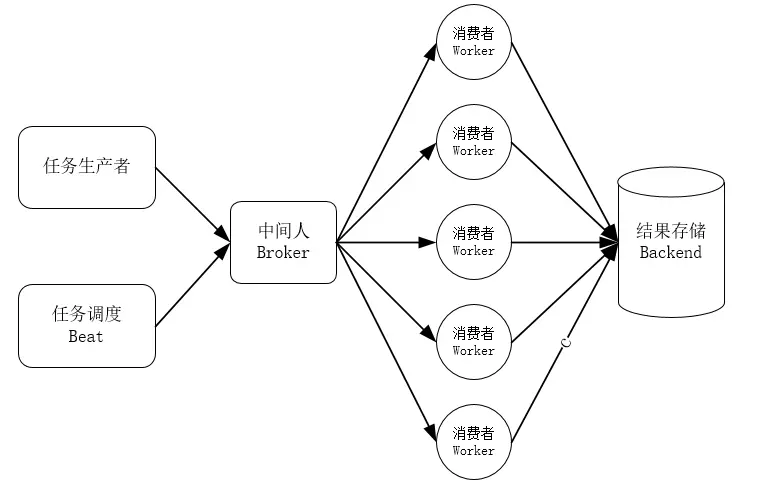
- 主要分为以下几个模块:
- 任务生产者:产生任务并把任务提交到任务队列中
- 任务调度Beat:Celery会根据配置文件对任务进行调配,可以按一定时间间隔周期性地执行某些任务
- 中间人Broker:相当于连接客户端和任务执行者worker,可以用rabbitMQ,也可以使用Redis
- 任务执行者Worker:它就一直监听任务队列,从中提取任务来执行,Worker可以运行在多台机器上,只要它们是连接在同一个broker上
- 结果存储:就是把Worker执行后的结果存储起来,需要的话直接从里面提取就好,不需要也可以不用管
- 主要分为以下几个模块:
-
modelfirst dbfirst区别?
- db first:就是代表数据库优先,先创建数据库
- model first:就是代表模型优先,先创建模型类,在根据模型类自动生成数据库
- 区别:在数据结构发生变化时,db frist编程方式是选择从数据库更新模型类;而model frist选择是从模型类生成数据库
-
线程/进程/协程区别
- 进程拥有独立的堆和栈,都不共享,进程有操作系统调度,是系统资源分配的独立单位
- 线程有自己独立的栈和共享的堆,一个进程里面可有多个线程,线程之间是平行的,它是cup调度和分配的基本单位
- 协程和线程一样共享堆不共享栈,调度完全由用户自己控制,是一种用户状态的轻量级线程
- 详解
-
tornado框架
-
栈、堆
- 栈:仅允许在栈顶进行入栈和出栈,且是后放进去的先出来,引用地址存在栈中
- 堆:可以看成一个完全二叉树,它是程序员运行时申请的动态内存,引用类型的值保存在堆中
- 如我们需要访问一个引用类型的值时,首先是从栈中取出该对象的引用地址,然后根据引用地址取出其堆中所需的数据
-
闭包
- 通俗来说,闭包相当于函数的嵌套,爱函数内部在定义一个函数,并且这个函数运用到了外函数的变量
-
你知道的排序算法
- 这里分享一下左神写的算法总结,这个也是我朋友推荐给我的,我感觉写的很好
-
Django模型类继承
-
ajax请求的csrf解决方法
-
redis为什么快?除了他是内存型数据库外,还有什么原因
- here
- FastDB:不知支持client-server框架,所以是用FasDB的程序必须在同一主机上
-
连接字符串用join还是+
- 两者的结果都是一样的,但是
join的性能会比+更好,因为当操作+连接字符串时,每执行一次+都会申请一块新的内存,而且join可以自定义字符串按照什么字符拼接
- 两者的结果都是一样的,但是